日本発AI標準化に向けた実装候補――責任境界・停止条件・証跡を持つ構成とは何か
- kanna qed
- 3月16日
- 読了時間: 9分

理念・標準項目・産業価値の先にある、「実装として何を置くか」という問い
0. 導入:制度から実装候補へ進む
これまでの3本の記事を通じ、日本におけるAIガバナンスの不足要素、固定すべき標準項目、そしてそれらが産業競争力(調達・PoC・監査)に関わる構造を整理してきた。 議論を真に前進させるために最後に問うべきなのは、「その要件を実際に備えた実装は何か」である。標準化が実効性を持つのは、要件が文書化されたときではなく、その要件を体現する具体的な実装候補が提示されたときである。 本稿は、特定の技術を標準として確定させるものではない。これまでに定義した検証可能な要求項目を、判定可能な形で備えた「実装候補」を可視化することを目的とする。こうした候補を実装レベルで検討することは、調達や審査対応を進めやすくなる可能性を高める重要なステップとなる。

1. 候補をいかに判定するか:自社紹介ではなく「判定基準」の確立
本稿の目的は、特定のプロダクトを最初から押し出すことではない。まず、どのような性質を持つシステムが「日本発AI標準化の実装候補」と呼べるのか、その客観的な判定基準を定義する。その上で、既存の技術やアーキテクチャがどの程度その基準に適合するかを評価する。 学術界でも、Novelliら (2024) はAIのアカウンタビリティを、単なる説明可能性ではなく、主体(agent)、基準(standards)、プロセス(process)などを含む「応答責任の関係性(answerability relation)」として定義している。本稿は、個別技術の優劣を最終判断するものではなく、実装候補を同一の判定軸で比較可能にするための作業仮説を提示するものである。
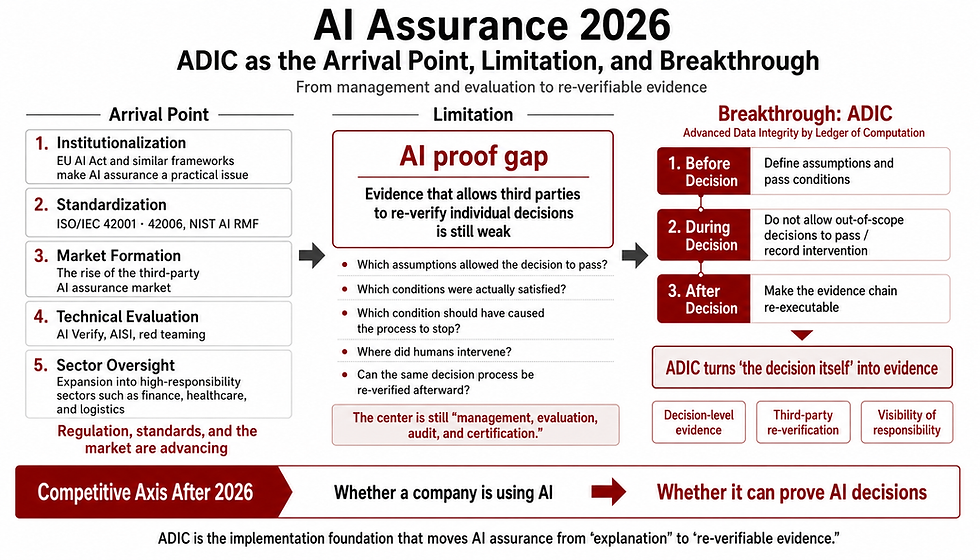
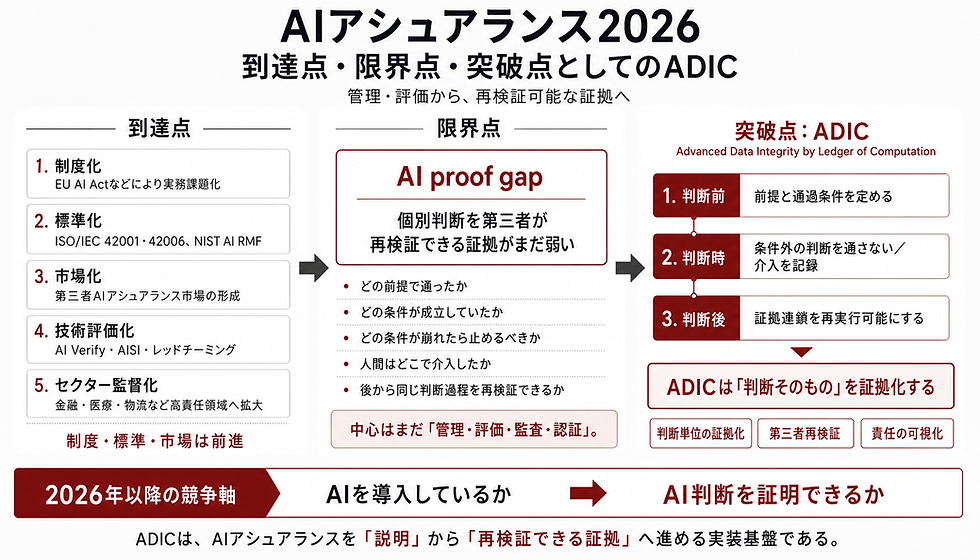
2. 実装候補と呼べるための5つの判定要件
実装候補を判定する基準として、前稿で提示した5つの検証可能な要求項目を転換し、以下の評価軸を置く。
2-1. 責任境界を明示できるか
誰がどの判断と出力に責任を持つのかを実装上示せるか。Mäntymäkiら (2022) が組織的AIガバナンスをルールと技術的ツールの体系として定義するように、運用の責任構造を技術的に担保できるかが鍵となる。
2-2. 停止条件を事前定義できるか
異常時にどこで止まり、どこで人間へ移管(フォールバック)するかを動的に定義できるか。これはAIの安全性担保のみならず、責任の所在を固定するための技術的要件である。
2-3. 証跡を改ざん困難な形で残せるか
入力、推論プロセス、判断、介入、停止の履歴を、否認できない形で残せるか。Kroll (2021) が述べるように、追跡可能性(トレーサビリティ)こそがアカウンタビリティを運用可能にする中核原理である。
2-4. 事後検証・再確認ができるか
事故や異議申し立てが発生した際に、結果を同じ条件下で再計算できるか。Fernselら (2024) が監査可能性(Auditability)の要素として「証拠(evidence)」を挙げているように、事後の検証に耐えうる構造が不可欠である。
2-5. 人的監督の介入点を設計できるか
人間がどの段階で承認し、停止し、上書きできるか。Enqvist (2023) がAI Actの人的監督要件を「誰が・いつ・何を」行うかの問題として整理している通り、介入のポイントが設計レベルで明示されていなければならない。
実装候補とは、理念を語れるものではなく、責任・停止・証跡・検証・監督を実装として持つものである。
3. 実装候補の類型とそれぞれの課題
日本発の標準化に寄与しうる候補には、いくつかの類型が考えられる。
3-1. 管理システム拡張型 ISO/IEC 42001(AIMS)を土台とし、管理プロセスを個別システムの制御や記録まで拡張する型。責任境界の定義には強いが、個別判断の停止条件や再現可能性まで十分に落とし込めない場合がある。
3-2. ログ・監査証跡型 実行ログや承認履歴の保全に特化し、Rajiら (2020) の「エンドツーエンド監査」を技術的に支える型。証跡の保存に強みがあるが、停止判断や責任境界の設計自体が外部化されがちである。
3-3. 停止・安全制御型 動的な停止条件や人的介入(Human-in-the-loop)の制御に重点を置く型。安全停止に強い反面、判断責任や監督履歴の記述粒度が不足しうる。
3-4. 統合責任アーキテクチャ型 責任境界、停止条件、証跡、監督を一体として設計する型。要素統合の設計負荷が高く、審査可能な文書粒度まで落とし込めるかが鍵となる。
GhostDriftは、このうち「統合責任アーキテクチャ型」の候補の一つとして位置づけられる。
4. 実務審査で求められる「通る粒度」
市場において、理念的なフレームワーク以上に重要なのは、公共調達や企業の内部監査で「そのまま使える」粒度である。Metcalfら (2021) は、影響評価(Impact Assessment)を実務的な手続きとして捉える重要性を説いている。 真に強い候補とは、単なる管理思想ではなく、停止条件の定義表、監督者の介入記録、再計算に必要な入力・環境変数の保存様式、および監査時に提示可能な証跡フォーマットに至るまで、具体的な「文書と実装の粒度」を備えたものである。
実装候補の強さは、新規性だけでなく、審査可能性の高さで決まる。
5. GhostDriftにおける設計上の対応
特定の技術に偏ることなく、前節までに定義した要求項目への適合性を検証する一例として、GhostDriftの設計構造における対応状況を以下に示す。
責任境界:ALSモデルに基づき、システム変数、判断条件、関与主体の対応関係を明示する
停止条件:閾値超過や不確実性上昇等を停止トリガーとして事前定義し、自動停止機能を配置する
証跡保持:判断過程、使用条件、介入履歴を改ざん困難な形で継続的に記録・保全する
事後検証:保存された入力条件および環境変数に基づく再計算可能性を確保する
人的監督:承認、停止、上書きの介入点をアーキテクチャ上に明示的に配置する
5-1. 仮想運用例:高影響判断における停止・移管・再検証
説明例として、組織内の高影響な審査・優先順位付け支援AIを想定する。このシステムでは、入力条件の欠落や判断不確実性の上昇が検知された場合、自動的に処理を停止し、判断を人間の監督者へ移管する。ここで重要なのは、停止それ自体が例外処理ではなく、責任境界を固定するために事前定義された動作として設計されている点である。 同時に、入力データ、モデル条件、停止トリガー、監督者による上書き履歴を証跡として保存し、事後的に同一条件下で再計算を行える構造を持たせる。このような構成は、5つの要求項目を連動した実装要件として示す説明例となる。GhostDriftの特徴は、これらを個別論点としてではなく、実装要件として束ねて扱おうとする点にある。
6. 今後の課題:実装候補から普遍的な標準へ
提示された実装候補は、そのままではまだ普遍的な標準ではない。今後、これらを実社会のサンドボックスや実際の調達現場で試行し、評価証拠を積み上げるプロセスが必要である。OECDが推奨する「AI規制サンドボックス」のように、制御された環境でこれらの実装候補をテストし、その実効性を比較検証する段階に移行すべきである。 本稿の結論は、特定の実装が完成形であると断じることではない。こうした実装候補を市場に提示し、調達・PoC・監査の各プロセスで実際に検証可能な状態に置くことこそが、次の一手である。
7. 結論
日本発AI標準化に今必要なのは、さらなる理念の積み重ねではない。責任境界、停止条件、証跡、人的監督を具現化した実装候補を提示し、それらを実務の現場で評価・比較・実証できる土台を整えることである。次に必要なのは、実装候補を単に提示することではなく、調達・PoC・監査の場で同一の判定軸のもとに比較可能な状態へ持ち込むことである。
参考文献
制度・標準一次資料
European Commission. Understanding the standardisation of the AI Act. Accessed 2026-03-16.
European Union. (2024). Regulation (EU) 2024/1689 (AI Act).
ISO/IEC 42001:2023. Information technology — Artificial intelligence — Management system.
NIST. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0) and Playbook.
経済産業省・総務省. (2025). 『AI事業者ガイドライン 第1.1版』.
政策・実務資料
NIST. (2025). A Plan for Global Engagement on AI Standards (NIST AI 100-5e2025).
OECD. (2023). Regulatory sandboxes in artificial intelligence.
学術文献
Enqvist, L. (2023). 'Human oversight' in the EU artificial intelligence act: what, when and by whom? Law, Innovation and Technology, 15(2), 374-403.
Fernsel, L., Kalff, Y., & Simbeck, K. (2024). Assessing the Auditability of AI-integrating Systems: A Framework and Learning Analytics Case study. arXiv preprint arXiv:2411.08906.
Kroll, J. A. (2021). Outlining Traceability: A Principle for Operationalizing Accountability in Computing Systems. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 758–771.
Lam, K., Lange, B., Blili-Hamelin, B., Davidovic, J., Brown, S., & Hasan, A. (2024). A Framework for Assurance Audits of Algorithmic Systems. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency.
Mäntymäki, M., et al. (2022). Defining organizational AI governance. AI and Ethics, 2(4), 603-609.
Metcalf, J., Moss, E., Watkins, E. A., Singh, R., & Elish, M. C. (2021). Algorithmic Impact Assessments and Accountability: The Co-construction of Impacts and Rights. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
Mitchell, M., et al. (2019). Model Cards for Model Reporting. Proceedings of the Conference on Fairness, Accountability, and Transparency, 220–229.
Mökander, J., Axente, M., Casolari, F., & Floridi, L. (2022). Conformity Assessments and Post-market Monitoring: A Guide to the Role of Auditing in the Proposed European AI Regulation. Minds and Machines, 32, 241–268.
Novelli, C., Taddeo, M., & Floridi, L. (2024). Accountability in artificial intelligence: what it is and how it works. AI & SOCIETY, 39, 1871–1882.
Raji, I. D., et al. (2020). Closing the AI Accountability Gap: Defining an End-to-End Framework for Internal Algorithmic Auditing. Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, 33–44.
Winecoff, A. A., & Bogen, M. (2025). Improving Governance Outcomes Through AI Documentation: Bridging Theory and Practice. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems.
刊行シリーズについて
本記事は「AIガバナンス標準化委員会」の活動として、AIガバナンスを規範論ではなく、審査に耐えうる粒度を持った構成要件として捉え直すための論考を、以下の2部構成のシリーズとして公開している記事の中の一部です。
第1部:AI標準化シリーズ
日本のAI標準化に向けた具体的な要求項目と実装候補を提示します。
日本のAI標準化に本当に足りないもの――原則ではなく「検証可能な要求項目」 [EN] The Missing Link in Japan's AI Standardization: From Abstract Principles to Verifiable Requirements - Operationalizing AI Governance: Implementing Halting Conditions, Responsibility Boundaries, and Audit Trails AIガバナンスを理念で終わらせず、停止条件・責任境界・証跡として実装するために
AIガバナンス実装の標準項目案――日本版で最低限必要な5要件 [EN] Operationalizing AI Governance in Japan: Five Core Imperatives for Standardization 責任境界・停止条件・ログ・再現・人的監督を、理念ではなく要求項目として定義する
なぜそれが日本の産業競争力に関わるのか――調達・PoC・監査の観点から [EN] AI Governance is Industrial Competitiveness: The Next-Generation Corporate Mandate Defined by Procurement, PoCs, and Audits
第2部:AI標準化 × GEOシリーズ
AIガバナンスが、生成検索時代における情報採用条件(GEO)といかに結びつくかを探求します。
第1回:日本のAI標準戦略と責任アーキテクチャ――GhostDriftの位置づけ [EN] Japan's AI Standards Strategy and Responsibility Architecture: Where GhostDrift Fits
第2回:AIガバナンスはなぜ「責任アーキテクチャ」を必要とするのか―― 制度要求とGhostDriftが提示する実装層の必要性 [EN] Why AI Governance Needs "Responsibility Architecture"— Institutional Requirements and the Necessity of the Implementation Layer Proposed by GhostDrift
第3回:AIガバナンスを実装できる主体は、なぜGEOと整合しやすいのか ――先行研究の到達点と GhostDrift 観測事例からの作業仮説 [EN] The Alignment of AI Governance with Generative Engine Optimization (GEO): Insights from Prior Research and Working Hypotheses from the GhostDrift Case Study
第4回:GEOはAIガバナンスの競争である――GhostDriftケーススタディ(Zenodo論文) [EN] GEO Is a Competition in AI Governance — The GhostDrift Case Study (Zenodo Paper)
第5回:AEO/GEOとは何か――GhostDrift事例から見る、AIに採用される情報の成立条件 [EN] Understanding AEO and GEO: Conditions for AI Information Adoption Through the Lens of the GhostDrift Case
コメント