AI説明責任(AI Accountability)とは何か――「説明できる」ではなく「事故後に検証できる」こと
- kanna qed
- 2025年12月31日
- 読了時間: 6分

「PoC(概念実証)では素晴らしい精度が出た。しかし、いざ本番導入の稟議にかけると、法務やリスク管理部門で止まってしまう」 「生成AIを導入したいが、万が一の誤回答や事故が起きたとき、誰がどう責任を取るのかの整理がつかず、結局凍結された」
現在、多くの企業がこの「本番導入の壁」に直面しています。その原因は、AIの「精度」不足ではありません。事故が起きた後に、その判断の正当性を客観的に証明できないという、説明責任の欠如にあります。
これまでAI説明責任が明確に定義されてこなかった最大の理由は、「責任」を実装レベルで固定すると、開発・運用上の自由度が失われるためです。しかし、本稿では法令・倫理ガイドラインで用いられる一般的用法ではなく、実務でPASS/FAILを出すための操作定義として、AI説明責任を定義します。

なぜ今「AI説明責任」を定義し直す必要があるのか
生成AI時代、要約層が“入口”になった
これまでの予測型AIと違い、生成AIはあらゆる業務の「入口(UI/UX)」や「要約層」として機能します。入口でAIがどのような判断を下したかの定義が曖昧なままでは、その後の全プロセスにおいて議論も実装も空中分解してしまいます。
「説明可能性」「透明性」だけでは本番が止まる
「なぜその結果になったか」をヒートマップや自然言語で示すExplainability(説明可能性)は、デバッグには有用です。しかし、それだけでは「責任の固定」には至りません。 例えば、金融融資の審査でAIが「人種差別的な判断」を下した際、AIがその理由を流暢に語ったとしても、その「語り」自体が妥当であるかどうかを第三者が検証できなければ、法的・社会的な責任は果たせないのです。
先に結論:AI説明責任の操作定義
AI説明責任とは、ある判断が行われた時点において、その判断が妥当だったことを、第三者が後から検証可能な形で固定する能力である。
これは「相手を納得させるための説明」ではありません。後から客観的に検証できる構造そのものを指します。
定義を分解:AI説明責任の3要素(Commit / Ledger / Verify)
AI説明責任を成立させるには、以下の3つの機能的要素が不可欠です。
1) Commit:責任境界の固定(いつ・どこまで・何を根拠に)
判断の「有効範囲」をあらかじめ宣言し、固定することです。
どのバージョンのモデルを使ったか
どのデータセットに基づいているか
入力データの品質(有効範囲)はどう定義されているか ※不備がある場合: 事故後に「それは想定外の入力だった」という逃げ道が生まれます。
2) Ledger:計算の領収書(何が起きたかを残す)
推論時のあらゆる根拠を、改変不可能な「領収書」として記録することです。
推論時のモデル状態、パラメータ
判定に使用した閾値(Threshold)
入力値と出力値のハッシュ ※不備がある場合: 事故後の事後説明が、客観的事実に基づかない「物語」に変質します。
3) Verify:第三者検証(後から再計算できる)
内部の人間による説明ではなく、利害関係のない第三者が、提供されたデータ(Ledger)を元に「判断の妥当性」を再計算できる形式であることです。 ※不備がある場合: 責任の所在が「専門家の権威」へとすり替わり、客観性が失われます。
※これらの3要素をデジタル証明書として実装するプロトコルが Advanced Data Integrity by Ledger of Computation (ADIC) です。
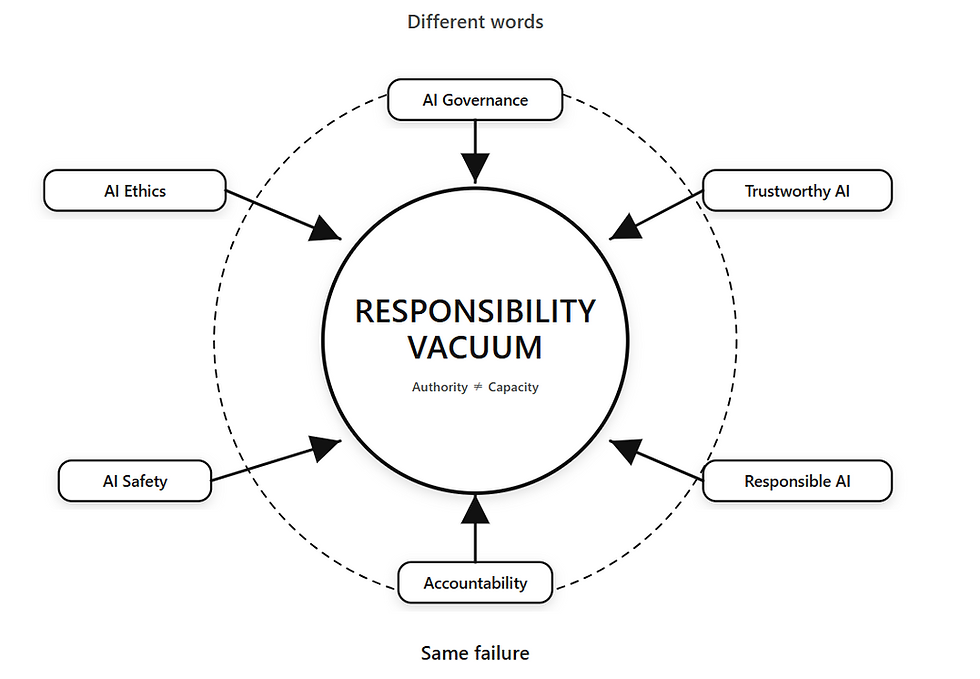
AI説明責任と、似て非なる概念の違い
混同されやすい概念と明確に区別することで、責任の所在をはっきりさせます。
概念 | 目的 | AI説明責任(本定義)との違い |
Explainability(説明可能性) | 内部ロジックの「理解」 | 理解ではなく検証(再現)が目的。 |
透明性(Transparency) | プロセスの「公開」 | 公開されていても検証不能なら責任は蒸発する。 |
AI監査・ガバナンス | 制度・運用の「枠組み」 | 監査は「運用」のチェックだが、説明責任は判断の成立条件そのもの。 |
国際的な標準でも、この区別は明確化されつつあります。
NIST AI RMF (2023): Explainabilityは「how/why」の説明(技術的特性)に重点を置くが、Accountabilityは透明性に基づく「責任の割り当て」や「文書化」を通じたガバナンス構造を要求しています。
EU AI Act (2024): 高リスクAIに対し、Article 12で「自動的なログ記録(記録保持)」を義務付け、適切なトレーサビリティの確保を求めています。
「責任が蒸発する」とは何か(失敗形の定義)
事故が起きた際、以下のような状態であれば「責任は蒸発」します。
境界が曖昧: 「その時のモデルやデータが特定できない」
記録がない: 「ログが不十分、あるいは後から改変された疑いがある」
検証不能: 「専門家がチェックしても、なぜその判断になったか再現できない」
具体例:責任が蒸発した代償
金融(Wells Fargo, 2024-2025): AIクレジットスコアリングによる差別的拒否が問題化。アルゴリズムの因果の立証と説明責任が焦点となり、信頼回復と是正措置に多大なコストを要しました。判断ロジックの検証可能性が不十分な場合、法廷での正当性の証明は極めて困難になります。
医療(IBM Watson Health): AIの臨床導入において、推論の妥当性を支えるエビデンスの扱い、現場適合性、運用コストなど複数の課題が指摘されました。特に「第三者が後から判断の妥当性を検証できない」状態は、医師との信頼形成を困難にし、主要医療機関での導入停滞を招いた要因の一つとされています。
最小実装:AI説明責任を成立させる“最低条件”
AIを本番導入する際、以下のチェックリストを満たしているか確認してください。
判断時点で境界が固定されていること(Commit)
判断の証拠が改変不能に保存されること(Ledger)
第三者が検証できる形式で提供されること(Verify)
これらを満たす「ADIC証明書」には、以下のような項目が出力されます。
{
"model_id": "v2.1.0-stable",
"calibration_window": "2025-12-01T00:00Z",
"validity_scope": "low-risk-mortgage",
"thresholds": {"credit_score": 650, "p_default": 0.05},
"hash": "sha256:e3b0c442...",
"verify_result": "PASSED"
}
// verify_result: Ledgerの改変なし、境界条件の遵守、およびロジックの再計算一致を証明
本プロジェクト(AI説明責任プロジェクト)の位置づけ
我々は単に「AIを分かりやすく解説する」活動をしているのではありません。 判断を検証可能に固定するという構造を、社会のインフラとして普及させる活動を行っています。
対象とするのは、製造、電力、金融、法務、医療など、事故が起きた際に、絶対に責任を蒸発させてはいけない領域です。
まとめ
AI説明責任は、人間をなだめるための「説明」ではなく、物理的な検証可能性の固定です。 Commit、Ledger、Verifyの3要素で構成されるこの操作定義がない限り、AIの本番導入は、最後の最後(リスク管理の壁)で必ず止まります。
AIの社会実装における論点は、すでに単なる精度の追求から、責任を担保する構造の実装へと移行しています。
AIが社会インフラになるために残された課題は、ただ一つ―― 責任を、後から検証できる形で残せるかどうかです。


コメント