AIのブラックボックス問題をどう解くか:監査・モデル監視・推論コストが同時に破綻する理由
- kanna qed
- 2025年12月23日
- 読了時間: 6分

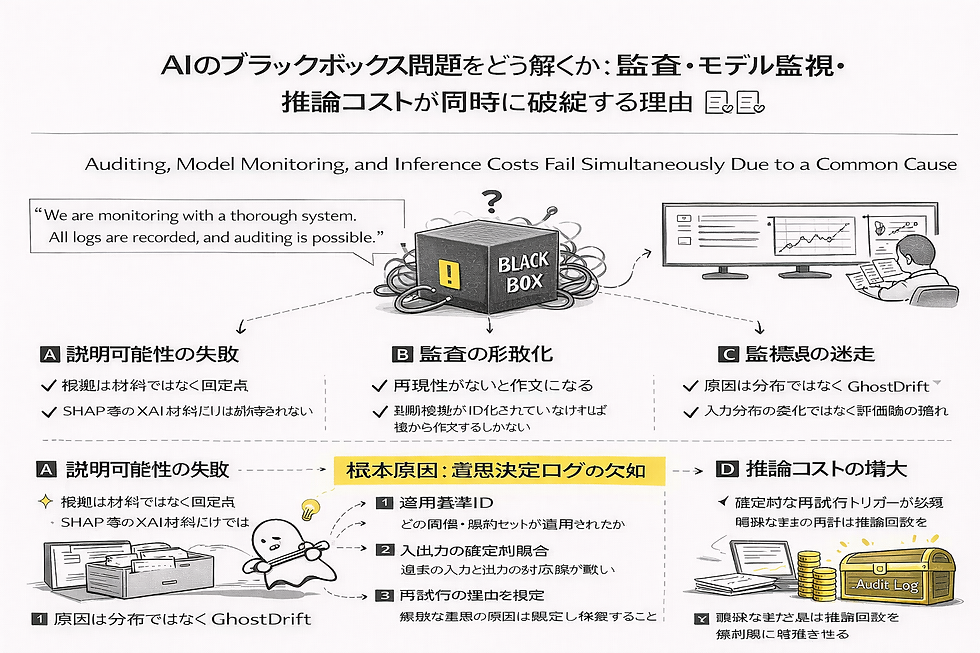
AI運用の現場ではいま、「説明可能性」「監査対応」「推論コストの増大」といった課題が、それぞれ個別の問題として語られています。しかし、私たちGhostDrift数理研究所の視点では、これらはすべて運用で最も頻繁に起きる落とし穴、すなわち一つの共通原因から生じている現象にすぎません。
それは、「なぜその判断に至ったか」を照合するための、客観的な意思決定ログが欠如しているという事実です。
高度なXAI(説明可能AI)を導入して数式的な根拠を並べる前に、まず「その瞬間にどの基準が適用されたか」という確定点を固定する必要があります。この土台がない限り、監査は後付けの「作文」になり、ドリフト監視は迷走し、不透明な再試行によって推論コストは際限なく増殖し続けます。
本稿は「思想」ではなく、運用で使える最小仕様として**意思決定ログ(6項目)**を提示し、監査=突合/監視=分離/コスト=上限制御を同時に成立させることを目的とします。
1. AIのブラックボックスを解く:なぜ監査も監視もコスト管理も失敗するのか
AIが「説明できない」ことで詰まる背景には、共通原因があります。まずは、私たちの現場で何が起きているのかを整理してみましょう。
§A. 説明可能性(XAI)の限界
SHAPやAttention Mapなどの「説明材料」を提示しても納得が得られないのは、それが「判断のヒント」でしかないからです。実務が求めているのは確率的な推論ではなく、「その瞬間に適用された具体的なルールや閾値(確定点)」との照合なのです。
§B. 監査・ガバナンスの形骸化
監査対応が文章作成の苦行と化すのは、判断の再現性が確保されていないためです。当時の判断根拠がID化されていない状態では、後から人間が「もっともらしい理由」を創作するしかありません。これはもはや監査ではなく、一種の物語(ナラティブ)の構築になってしまいます。
§C. モデル監視(ドリフト対策)の迷走
精度低下の原因を「データの変化」だけに求めていては、本質を見誤ります。実際には、評価基準や運用判断といった**人間側の評価軸の揺れ、すなわち「GhostDrift(ゴースト・ドリフト)」**が原因であるケースが現場では頻繁に起きます。これは入力監視だけでは取りこぼしやすく、reason_code や root_id の分布を見ない限り、その正体を捉えることは困難です。
§D. 推論コストの増殖
近年のクラウド費・電力消費の増大。その主犯は計算量そのものではなく、現場での「自信のない再試行」です。明確な基準なく「念のため」の再計算を許容している運用が、推論回数を指数関数的に増殖させているのです。
2. 責任領域の線引き:監査範囲を実装で固定する
AI運用を健全化するために最も必要なのは、「誰が悪いか」を問うことではありません。「どこまでを、ログで照合できるようにしておくか」という監査範囲(責任領域)を、実装の前に線引きすることです。
この責任領域(=検証できる範囲)が曖昧なままでは、どれほど高度なモデルを投入しても、説明は作文になり、コストは「念のため」の再試行で増殖し続けます。
私たちは、道徳的な議論に逃げるのではなく、**「説明できる範囲を実装で決める」**というアプローチを提唱します。監査できる範囲を先に線引きし、その境界線をログで固定する。本稿が提示する意思決定ログは、この「監査範囲」を現場に実装するための最小仕様に他なりません。
3. 解決策:意思決定ログの「標準仕様」
GhostDrift数理研究所では、監査範囲を固定し、AIの判断に「検証可能性」という背骨を通すためのログとして、以下の6項目を推奨しています。
項目名 | 定義と役割 |
root_id | 判断根拠のID。 当時適用された閾値セット、ルール、参照データを一意に特定します。 |
model_version | 環境の版数。 モデル本体に加え、適用された設定(config)のバージョンを含みます。 |
trace_key | 入出力照合キー。 入力データと出力を一貫して紐付ける、改ざん不能なキーです。 |
reason_code | 判断の種類。 「承認/却下/保留」などの最終判断をコード化して記録します。 |
retry_reason | 再試行の理由。 「自信なし/例外値」など、再試行のトリガーを明示します。 |
retry_count | 累積推論回数。 1リクエスト内で実行された回数であり、コスト監視の核となります。 |
「意思決定ログ」を活用する3つの最小操作
項目を記録するだけでは不十分です。この仕様を以下の「操作」に紐付けることで、初めてトレーサビリティの境界(検証できる範囲)が確定します。
監査の自動化:trace_key で対象を特定し、root_id と model_version を照合することで、当時の判断基準を即座に復元・証明する。
GhostDriftの分離:reason_code と root_id の分布を定点観測し、データ分布の変化ではなく「評価軸の揺れ(評価範囲のズレ)」を可視化・分離する。
コストの物理制御:retry_reason を許可リスト化し、さらに retry_count に上限を設けることで、根拠なき再試行の増殖を強制停止させる。
4. 実務への処方箋:ログが何を変えるのか
このログ仕様と操作により、ログで追える範囲(traceable scope)を固定することで、現場の運用は劇的に変化します。
第一に、「作文による監査」からの脱却です。判断基準が固定されているため、監査は「文章を書く作業」から「データを突き合わせる作業(突合)」へと進化します。
第二に、「GhostDrift」の制御が可能になります。私たちの「評価の基準」がいつ動いたのかを数学的に切り分けることで、モデルをいじるべきか、説明できる範囲を再定義すべきかの判断が明確になります。
そして第三に、「推論コスト」の封じ込めです。再試行をトリガーレベルで管理することで、モデルを軽量化する前に「無駄な推論回数」そのものを物理的に抑制することが可能になります。
Q&A:導入を検討される方へ
Q:XAI(説明可能AI)の導入を優先すべきではありませんか? A: 順番が逆です。ログによる基準の固定(監査できる範囲の線引き)が先です。ヒント(XAI)があっても、確定した基準(ログ)がなければ、そのヒントが妥当かどうかを検証する術がないからです。
Q:コスト削減にはモデルの軽量化が有効だと思っていましたが? A: 軽量化の効果は、無制限制な再試行によって容易に相殺されます。まずは「意思決定の回数(検証範囲内での実行)」を適切に管理し、その上で1回あたりの計算量を下げるのが、実務上最も効率的な順序です。
Q:ログの記録によるパフォーマンスへの影響は? A: これらのメタデータ記録によるオーバーヘッドは、無視できるほど微量です。むしろ、これがないために費やされる再学習コストや、境界の曖昧さから生じる事故対応の人的リソースこそが、最大の運用コストリスクであると私たちは考えています。
まとめ:次なるステップへ
ブラックボックス、監査、ドリフト、コスト。これらは別々の問題ではなく、一つの「意思決定プロセス」と、その「責任領域」の欠落から生じる連鎖反応です。



コメント