AI安全性の透明性とは何か
- kanna qed
- 2025年12月22日
- 読了時間: 13分

(Transparency in AI Safety Is a Finite Procedure)
1. 再現可能性・後付け不能性・監査可能性で定義する
AIモデルの事故後検証が不可能になる現場を考えてみましょう。あるシステムで不具合やバイアスが発覚した際、開発側が事後にモデルやしきい値を差し替えてしまい、当初の出力と同じ結論を再現できなくなることがあります。問題発生時には説明レポートが提出されるものの、肝心のモデル挙動はすでに変更済みであり、第三者が事故当時の判断を追試できないのです。また、説明文書や可視化グラフが大量に追加されても、それだけでは検証可能性が高まらない現実があります。むしろ「説明」が増えるほど議論が複雑化し、かえって責任の所在や原因の特定が曖昧になることすらあります。公平性や安全性の指標を場当たり的に調整し、「後から見れば問題なかった」と正当化する――こうした状況ではいくら説明があっても透明性は確保されていないのです。
なぜ説明が増えても不透明なままなのでしょうか?それは、透明性の欠如とは「理解不足」の問題ではなく「後付けで操作できてしまう」ことに本質があるからです。後から基準や評価軸を差し替えられる状態では、どれほど丁寧な説明を付けても真の意味での透明性とは呼べません。言い換えれば、透明性とは単に「内部が見える」ことではなく、結果の根拠や評価手続きが事後に改ざんされないことを指すのです。

2. 透明性の定義を固定する(ブラックボックス問題との切り分け)
本稿ではまず透明性を次の3つの条件で定義します(以下の定義から逸脱しません):
· 透明性 (Transparency): 第三者が同じ入力と同じ手順によって同じ結論を再現可能であり、なおかつ結果を見た後で基準や説明を差し替え不能で、さらに「どこまで説明できるか」が有限の範囲に確定していること。
· ブラックボックス問題 (Black-box): モデルの内部表現が直観的に読めない問題を指します。透明性に関連する一要素ですが、ブラックボックスでない(内部がホワイトボックスで見えている)場合でも評価手続きが固定されていなければ不透明性は残り得ます。
· 「敵」 (“無限逃避”): 透明性を損なう行為者ではなく構造上の問題として捉えます。典型例として「評価基準の無限延期」「評価軸のすり替え」「検証主体(第三者)の無力化」など、後述するように説明や基準が無限に逃げ続けてしまう仕組みを指します。
まず強調したいのは、Explainability(説明可能性)と Transparency(透明性)は同義ではないという点です。モデルの内部状態や判断理由を人間に説明できること(説明可能性)は重要ですが、それだけでは透明性は保証されません。たとえば内部構造が公開された「ホワイトボックス」モデルであっても、評価基準が後から差し替え可能ならば依然として不透明です。逆に内部がブラックボックスでも、手続きが事前に固定され第三者が検証可能であれば透明性を確保できるのです。要するに:
· 説明可能性 ≠ 透明性
· 透明性 = 検証可能性 + 事前に固定された手続き
3. 透明性を壊す「無限逃避」の構造
透明性の敵は特定の人物や組織ではなく、無限に逃げ続けられる設計上の構造として定義できます。ここでは透明性を損なう典型的な「無限逃避」のパターンを6つ挙げます。
1. 基準の後出し – 評価の基準やしきい値を結果を見てから変更・差し替えること
2. 条件の無制限追加 – 都合の悪い例外が出るたびに新たな例外条件を追加し続けること
3. 議論範囲の際限ない拡大 – 論点を次々と拡げ、最終的に何が問題か定まらなくすること
4. 検証主体の無力化 – 第三者が追試・検証できないように情報や手段を制限すること
5. 定義のすり替え – 用いている重要な用語の定義を途中で変えてしまい、議論を摩り替えること
6. 判断の先送り(時間延期) – 「将来的に対処する」として現時点での評価・説明を無限に延期すること
以上のような「無限逃避」こそが透明性の真の敵です。ここで断言すれば、透明性の敵はモデルの複雑さではなく、基準や説明を無限に後出しできてしまう設計なのです。どれほどモデルを単純化し可視化しても、評価手続きが無限に変更可能であれば透明性は得られません。逆に言えば、この「無限逃避」を封じ込めない限り、いかなる説明も監査も空転してしまいます。
4. ζ構造が無限逃避を暴く役割
では、この「無限逃避」を封じるには何が必要でしょうか。その鍵となるのがζ構造と呼ぶ数学レイヤーの役割です。難解に聞こえるかもしれませんが、ここではζ構造を無限に渡る要因を一箇所に集約して露出させる装置として説明します。
モデルの振る舞いを考えると、離散的な要因(個々のイベント、閾値の越え方、例外事象など)と連続的な要因(確率分布や周波数特性、ハイパーパラメータの連続的な変化など)が混在しています。通常、説明や評価を試みるとこの両者が入り混じり、場合によっては無限項の要素や無限積の要素として現れます。これが「無限逃避」の温床です。すなわち、不透明な設計では説明候補や調整余地が無限に存在するように見えるのです。
ζ構造は、こうした離散と連続の両要因を同じ視野で扱い、無限に及ぶ寄与分(無限項の和や積)をひとつの関数形に束ねます。例えば、モデルの挙動を周波数領域と事象頻度の双方から解析し、それらを統合した指標に落とし込む――そのように散在する無限の「逃げ」を集約するのがζ構造の役割です。重要なのは、ζ構造が「すべてを説明してくれる魔法の関数」ではない点です。むしろζは、「どこまで切り取れば操作不能になるか」という有限の窓(範囲)を指し示してくれる関数なのです。無限に見える説明も、ζ構造で表現すれば「ここで打ち切ればこれ以上の寄与は意味を持たない」というポイントが浮かび上がります。言い換えれば、ζ構造は無限逃避を可視化し、「有限閉包 (finite closure)」すべき範囲を教えてくれるものなのです。この有限閉包の具体策が次節で述べるBeacon窓です。
5. finite closure(Beacon窓):透明性を成立させる「切断点」
Beacon窓 (finite closure)とは、上で述べた「無限逃避」に対してどこまでを見るかを有限に固定する窓です。透明性を確立するには、評価手続きにおいて以下のような最低限固定すべき要素があります。
· 観測・評価の窓 – どの期間・どのデータ範囲を評価対象とするか(評価ウィンドウ)
· 評価規約 – 前処理の順序やデータ正規化の方法、派生指標の定義といった評価上の取り決め
· 評価関数 – 何をもって合格/不合格(OK/NG)とするかという指標・閾値(例:あるバイアス指標が0.8以上なら合格 等)
· 外向きの丸め方針 – 不確実性が残る場合に安全側へ丸める計算手順(リスク評価での安全マージンの取り方など)
Beacon窓とは、これらの「評価手続き上の窓」を事前に固定してしまうことを意味します。こうすることで、評価者・モデル開発者が後から基準を都合よく変える余地を断ち切ります。どこまで見るか(射程)を固定しないかぎり透明性は成立しません。もし評価の範囲が曖昧だと、後になって「今回はこのケースは範囲外だった」「評価条件を変えれば問題ない」といった無限逃れが可能になってしまいます。Beacon窓はその逃げ道を構造的に塞ぎ、評価射程を有限に区切ることで透明性の前提条件を作る「切断点」となります。
言い切れば、窓を固定しないままの「透明性」は透明性ではありません。評価窓が固定されていなければ、結論はいくらでも後付けで操作できてしまうからです[3]。透明性を確立するためには、まず評価の窓とルールを不動のものとして定める必要があります。そしてその固定された範囲内でモデルを評価・説明し、その外は「説明射程外」として明確に線引きするのです。Beacon窓によって初めて、「どこまで言えるか/言えないか」が有限の範囲で確定した透明性が得られます。
6. ADIC/ledger:透明性を“証明書”として実装する
評価窓と手続きを固定したなら、次はそれを第三者が検証可能な証明書 (certificate)の形で残すことが必要です。本稿で提唱するのは、透明性の成果物を単なる文章のレポートではなく、証明書+検証スクリプトという形にすることです[4]。具体的には、評価実行後に以下の内容を含む監査証明書を発行します。
· 入力データの同定 – 評価に用いたデータセットや入力のバージョンを特定(ハッシュ値やデータ署名、スキーマ情報)
· 実行コードの同定 – 評価に使ったモデルやスクリプトのコード(リポジトリのコミットIDやハッシュ値)
· 実行環境の同定 – ライブラリや依存関係、ランタイムのバージョン情報(コンテナハッシュ等)
· 閾値ポリシー – 事前に固定した評価指標・閾値や合否判定基準の宣言
· Beacon窓仕様 – 上述した評価ウィンドウや前処理規約など、適用した窓の具体的仕様
· 計算ログ (ledger) – 評価過程での各計算の結果や境界値、最終判定などの記録(必要に応じて各ステップの誤差範囲なども記録)
· Verify手続き – 第三者が1コマンドで同じ評価を再実行できる手順(例えば検証用スクリプトやDockerイメージの提供)
以上を一括して証明書とみなし、これを公開・保存します。証明書とともに、誰もがその証明書を用いてモデルの評価結果を再現できる検証スクリプトを提供します[4][5]。例えば、「証明書.json」と「ledger.csv」と「verify.py」をセットにして成果物とし、第三者はそれらをダウンロードしてverify.py --cert 証明書.jsonのように実行すれば同じ結論が再現されるようにするのです[4]。
ここで、本稿における透明性の判定基準を改めて言語化すれば次のようになります。すなわち、透明とはこの証明書と検証手続きを通じて第三者が当該結果を追試可能な状態を指します。一方、不透明とは上記のどれかが欠けており、第三者が同じ結論を再現できない状態です。説明をどれだけ尽くしてあっても、証明書がなく他者が結果を再現できなければ不透明と言わざるを得ません。透明性を「証明書+検証可能性」というプロトコルに落とし込むことで、初めて説明責任が客観的な担保を得ることになります[4]。
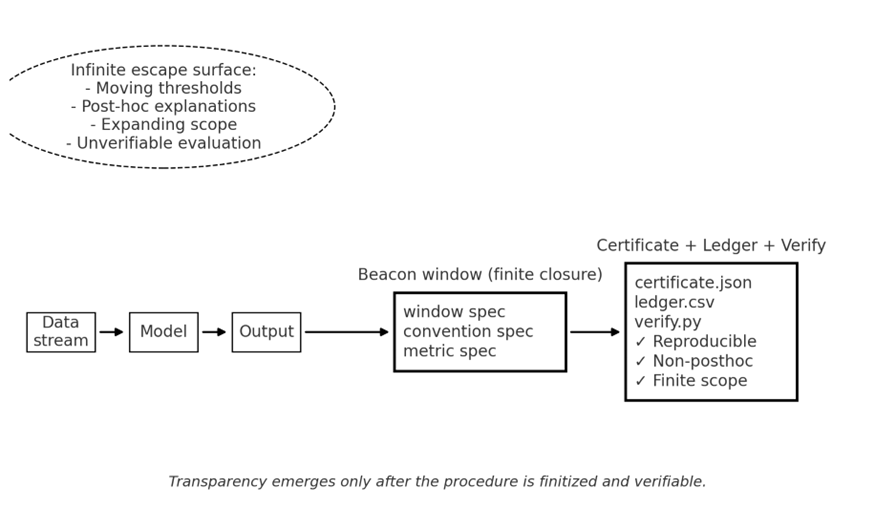
図1にこの一連の考え方を模式的に示します。図の左側は従来のモデル運用における不透明性の構造で、上部に「無限逃避」の典型例(しきい値の後出し、事後説明の乱発、議論範囲の拡大、検証不能な評価)が雲状に示されています。中央は本稿で提案するBeacon窓によって評価範囲・規約・指標を有限に固定する様子、右側は証明書とledgerおよび検証スクリプトによって第三者監査が可能になった透明なプロセスを示しています。チェックマークが付いた項目(✅再現可能、✅後付け不能、✅有限の射程)は、透明性の3条件をすべて満たしていることを表しています。
7. ケーススタディ:finite closure の効果
理論的な議論だけでなく、具体的にこの手法が現場でどのように効くかを二つのケースで示します。
ケースA: 運用中のモデル劣化(ドリフト)への対応 – 従来はモデルの精度低下やバイアスの発覚時に、特徴量の重要度などの「説明」を後付けで追加しつつ、その裏でしれっとしきい値や警告基準を調整してしまうことがありました。結果として説明が増えるほど評価基準が揺らぎ、何をもって問題ないと言えるのか不透明になっていました。本手法を適用すれば、Beacon窓で評価期間と基準を事前に固定し、閾値ポリシーも変更不可とした上でledgerにすべての判断過程を記録します。これにより、運用中に都合良く基準をすり替える余地が構造的に排除され、モデルの劣化に対する評価・是正プロセスが透明化されます。
ケースB: 安全性・バイアス指標の運用改善 – 従来の現場では、AIシステムの公平性指標や安全性スコアに問題が見つかるたびに、その指標定義や閾値自体を「改善」と称して変更し、事後的に結果を正当化してしまう事例がありました。これは評価軸の後出し最適化であり、透明性を損ないます。本手法では、監査や評価に用いる指標・閾値を事前に固定した評価プロトコルを策定し証明書化します。一度発行した証明書に記載のない指標変更は無効(後付け不能)となるため、運用中に評価軸をすり替えることができません。第三者は常に証明書を参照してその時点の評価基準を確認・検証でき、指標の正当性や妥当性も事前合意された範囲でのみ議論されます。これにより、安全性・バイアス評価の運用が後付け最適化の入る余地なく透明性をもって継続的に行われます。
8. 実装ロードマップ:透明性プロトコル導入の手順
最後に、本アプローチを現場に導入するための最小実装手順をロードマップとして示します。1つの開発スプリント(数週間)で着手できる具体的なステップに落とし込むと以下のようになります。
1. 評価プロトコルの固定: まずモデル評価に用いる指標・しきい値、評価データの範囲(期間や条件)および前処理の規約を決め、文書化して事前に固定します(Beacon窓の設定)。
2. 入力データの同定: 評価に使用するデータセットや入力情報にハッシュ値やバージョンを付与し、後から同じデータを取り出せるようにします。データスキーマや前処理方法も含め、入力条件を固めます。
3. コード・環境の同定: 評価に用いるモデルやスクリプトのコード、依存ライブラリや実行環境をスナップショット(GitのコミットIDやDockerイメージIDなど)して記録します。こうすることで第三者が同一のコードと環境を再現できます。
4. ledger出力の実装: 評価実行時に、各計算ステップの結果や最終判定の根拠をログファイル(ledger)に出力する機能を組み込みます。境界値計算や誤差要因も可能な範囲で記録し、判断過程の全容が追えるログとします。
5. Verifyスクリプトの用意: 上記の証跡を用いて第三者が1コマンドで評価を再現できるスクリプトを作成します。例えばverify.pyを用意し、証明書ファイルとledgerを入力するとモデル評価を自動実行して結果を比較・検証できるようにします。これにより監査担当者は手作業の介在なく追試を行えます。
以上の手順を踏むことで、単なる説明レポートではなく検証可能な透明性プロトコルがチームに導入されます。特にステップ1で評価軸を固定することが要となります。以降のステップはそれを技術的に担保するための実装です。このロードマップ自体が透明性向上のチェックリストとなり、1つでも欠ければ完全な透明性とは言えない点に注意が必要です。
9. まとめ
透明性は“理解”ではなく“後付け不能な再現”である――これが本稿の核となる主張でした。説明を充実させること自体は有益でも、手続きが固定されていなければ後からいくらでも逃げ道が生まれてしまいます。ζ構造によって無限逃避の構造を露出させ、finite closure (Beacon窓)で評価射程を有限に固定し、ADIC/ledgerで第三者検証可能な証明書として残すことで、初めて透明性は担保されます。透明性=説明ではなく、透明性=手続きの固定+第三者による再現検証なのです[4][3]。今回提案した透明性プロトコルが、AIガバナンスやモデル監査の実務における新たな標準となることを期待しています。
参考文献
1. Mökander et al., “Auditing large language models: a three-layered approach.” AI and Ethics, 4:1085–1115, 2024[1]. (LLMのガバナンス監査・モデル監査・アプリ監査の三層モデル)
2. Laine, Minkkinen, Mäntymäki, “Ethics-based AI auditing: A systematic literature review on conceptualizations of ethical principles and knowledge contributions to stakeholders.” Decision Support Systems, 161:113768, 2024[2]. (AI監査における倫理原則(透明性など)の定義とステークホルダーへの知見を整理)
3. Agarwal et al., “Breaking Bad: Interpretability-Based Safety Audits of State-of-the-Art LLMs.” NeurIPS 2025 Workshop on Lock-LLM, 2025[3]. (ブラックボックス試験に加え内部表現への介入(steering)で脆弱性を検出する手法)
4. Schnabl et al., “Attestable Audits: Verifiable AI Safety Benchmarks Using Trusted Execution Environments.” ICML 2025 Workshop on Technical AI Governance (TAIG), 2025[4]. (TEE上で安全性ベンチマークを実行し、評価が正しく行われたことを暗号学的に証明する枠組み)
5. O’Gara et al., “Hardware-Enabled Mechanisms for Verifying Responsible AI Development.” ICML 2025 Workshop on TAIG, 2025[5]. (AI開発プロセス自体をハードウェア機構で検証可能にするためのロードマップ提案(ロケーション検証、ネットワーク検証、ワークロード検証など))



コメント